Day 4 (Developer Day) of WWW2004 kicks off with an 8:30 A.M. morning keynote. There are many fewer people here this morning, maybe 150. I remembered the camera today so expect more low quality, amateur pictures throughout the day. About three minutes before the conference closed, Stuart Roebuck explained why none of the microphones worked on my PowerBook. I'll know for next time.
The Developer Day Plenary is Doug Cutting talking about Nutch, an open source search engine. His OpenOffice Impress slides "totally failed to open this morning" so he reconstructed them in 5 minutes. He contrasts Nutch with Lucene. Lucene is a mature, Apache project. It is a Java library for text indexing and search meant to be embedded in other applications. It is not an end-user application. JIRA, FURL, Lookout, and others use Lucene. It is not designed for site search. "Documentation is always a hard one for open source projects to get right and books to ?tend to? help here."
Nutch is a young open source project for webmasters, still not end users. It has a few part time paid developers. It is written in Java based on NekoHTML. It is a search site, but wants "to power lots of sites". They may modify the license in the future. They may use the license to force people to make the searches transparent. "Algorithms aren't really objective." It's a research project, but they're trying to reinvent what a lot of commercial companies have already invented. The goal is to increase the transparency of the web search. Why are pages ranked the way they are? Nutch is used by MozDex, Objects Search and other search engines.
Technical goals are scaling well, billions of pages, millions of servers, very noisy data, complete crawl takes weeks, thousands of searches per second, state-of-the-art search result quality. One terabyte of disk per 100 million pages. It's a distributed system. They use link analysis over the link database (various possible algorithms) and anchor text indexing (matches to search terms). 90% of the improvement is done by anchor text indexing as opposed to link analysis. They're within an order of magnitude of the state of the art and probably better than that. Calendars are tricky (infinite page count). Link analysis doesn't help on the Intranet.
In Q&A a concern is raised about the performance of using threads vs. asynchronous I/O for fetching pages. Cutting says he tried java.nio and it didn't work. They could saturate the ISPs' connections using threads. The I/O API is not a bottleneck.
Paul Ford of Harper's is showing an amusing semantic web app. However, it uses pure XML. It does not use RDF. They do have taxonomies. "It's all done by hand." At least the markup is doen by hand in vi and BBEdit. This is then slurped up in XSLT 2 (Saxon), and HTML is spit out onto the site. It was hard to get started but easy to keep rolling. RDF is not right for redundant content and conditionals. They can use XSLT to move to real RDF if they ever need to. This is in the semantic web track, but it occurs to me that if this had been presented five yhears ago we would have just called it an XML app. They do use a taxonomy they've developed, but it's all custom markup and names. They aren't even using URIs to name things as near as I can tell. The web site published HTML and RSS. The original marked up content is not published.
The MuseumFinland is trying to enable search across all 1000 or so Finnish museums.
The Simile Project is trying to provide semantic interoperability for digital library metadata. "metadata quality is a function of heterogeneity" Open questions for the semantic web: How do you deal with disagreements? How do you distinguish disgareements from mistakes?
This conference is making me think a lot about the semantic web. I'm certainly learning more about the details (RDF, OWL etc.). However, I still don't see the point. For instance what does RDF bring to the party? The basic idea of RDF is that a collection of URIs forms a vocabulary. Different organizations and people define different vocabularies, and the URIs sort out whose name, date, title, etc. property you're using at any given time. Remind you of anything? It reminds me a lot of XML + namespaces. What exactly does RDF bring to the party? OWL (if I understand it) lets you connect different vocabularies. But so does XSLT. I guess the RDF model is a little simpler. It's all just triples, that can be automatically combined with other triples, and thereby inferences can be drawn. Does this actually produce anything useful, though? I don't see the killer app. Theoretically a lot of people are talking about combining RDF and ontologies from multiple sources too find knowledge that isn't obvious from any one source. However, no one's actually publishing their RDF. They're all transforming to HTML and publishing that.
Usability of RDF is a common theme among the semanticists. They all see various GUIs being used to store and present RDF. They all want to hide the RDF from end users. It's not clear, however, if there is (or can be, or should be) a generic RDF GUI like the browser is for HTML (or even XML, with style sheets).

After an entertaining lunch featuring Q&A with Tim Berners-Lee (shown above), I decided to desert the semantic web for the final afternoon of the show. Instead I've gone off to learn about the much more practical XForms. Unlikke the semantic web, I believe XForms really can work. My main question is whether browsers will ever implement this, or if there'll be other interesting implementations.
The session begins with a tutorial from the W3C's always entertaining Stephen Pemberton. He claims 20+ implementations on the day of the release and about 30 now. Some large companies (U.S. Navy, Bristol-Myers-Squibb, Daiwa, Frauenhofer) are already using this. He's repeating a lot of his points from Wednesday. XForms separates the data being collected and the constraints on it (the model) from the user interface.

What's d16n? It's not just for forms. You can also use it for editing XML, spreadsheet like apps, output transformations, etc.
Fields are hidden by default. There's no form element any more. I'm not sure I'm going to write any more about the syntax.
It's too hard to explain without seeing thre examples, and I can't type that fast, but it is quite clean. XForms support HTTP PUT! (and GET and POST. DELETE and WebDAV methods are not supported in 1.0 but may be added in the future.)
You can submit to XML-RPC and SOAP as well as HTTP servers.
And it works with all well-formed XML pages, not just XHTML (but not classic, malformed HTML). XForms has equivalents for all HTML form widgets, and may customize some according to data type. Plus it adds a range control and
an output control. There are toggles and switches to hide and reveal parts of the user interface. These are useful for wizards.
There are repeating fields like in FileMaker. It supports conditionals.
A single form can be submitted to multiple servers.
One thing strikes me as dangerous about XForms: they provide so much power to restrict what can be entered that server side developers are likely to not validate the input like they should, instead relying on the client to have checked the input. It would still be possible to feed unexpected input to the server by using a different server or a client that doesn't enforce the constraints.
An XForm result may replace only the form instance, not the whole page, but what then about namespace mappings, etc.? What is the URI of the combined page? This is a very tricky area.
T. V. Raman, author of XForms: XML Powered Web Forms, is talking about XForms accessibility and usability. "People get so hung up on RDF's syntax. That's not why it's there." He predicts that Mark Birbeck will implement a semantic web browser in XForms, purely by writing angle brackets (XForms code) without writing regular source code. According to Pemberton, CSS is adding a lot of properties specifically for use with XForms.

Next Mark Birbeck is doing a demo of FormsPlayer. "We've had a semantic web overload."

Pure Edge's John Boyer is speaking about security in in XForms. Maybe he'll address my question about server side validation of user input. Hmm, it seems sending the data as a full XML document rather than as a list of name=value pairs might solve this. It would allow the server to easily use standard validation talks. This talk is mostly concerned with XML digital signatures and its supporting technologies. Now on the client side, how does the client know what he or she is signing? If an XML document is transmitted, what's the guarantee that that XML document was correctly and fully displayed to the user? Is what you see, what you signed? e.g. was the color of the fine print the same as the background color of the page? It turns out they have thought of this. The entire form document, plus all style sheets, etc, are signed.

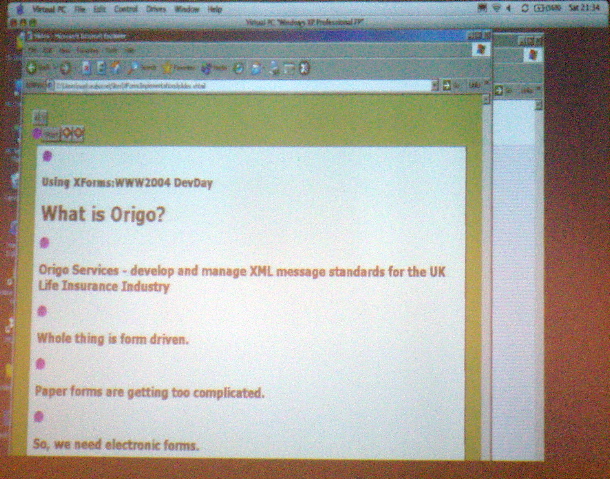
The last speaker of the afternoon (and the conference) is Mark Seaborne, who will be talking about using XForms. His slide show is in an XForm. He's using an XForm control to step through the forms! He works in insurance in the UK, an industry that's completely paper forms driven. It's important that the users not have to fill in the full form before rejections are detected. "There's a huge number of projects listed on the W3C website, but most of them aren't finished and some of them are actually dead." There are lots of different bugs and inconsistencies between different implementations, many of which have to do with CSS. IBM has announced that they're starting work on putting XForms support into Mozilla.
That's it. The show is over. Go home. I'm exhausted. I'll see you on Monday.