Table of Contents
In all of XML, I have found nothing quite so hard to understand yet easy to do as writing SAX filters. For a long time, it felt like I had a mental block preventing me from grokking just how filters worked, and yet every time I wrote one it almost always worked on the first try. In fact, even when I was convinced that the code I had written could not possibly work, it did. I can’t decide whether this is an example of wonderful or awful API design.
The basic idea of filters is that an XMLReader, instead of receiving XML text directly from a file, socket, or other source, receives already parsed events from another XMLReader. It can change these events before passing them along to the client application through the usual methods of ContentHandler and the other callback interfaces. For example, it can add a unique ID attribute to every element or delete all elements in the SVG namespace from the input stream.
Figure 8.1 diagrams the normal course of XML processing. A client application instructs a parser, represented in SAX by an XMLReader object, to read the text of an XML document. As it reads, the parser calls back to the client application’s ContentHandler.
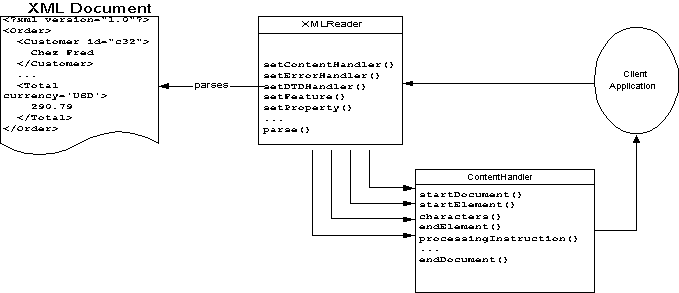
Figure 8.2 diagrams the course of XML processing with a filter. A client application instructs the filter, represented in SAX by an XMLFilter object, to read the text of an XML document. The filter then instructs the parser to read the text of an XML document. As it reads, the parser calls back to the filter’s ContentHandler. The filter’s ContentHandler then calls back to the client application’s ContentHandler.
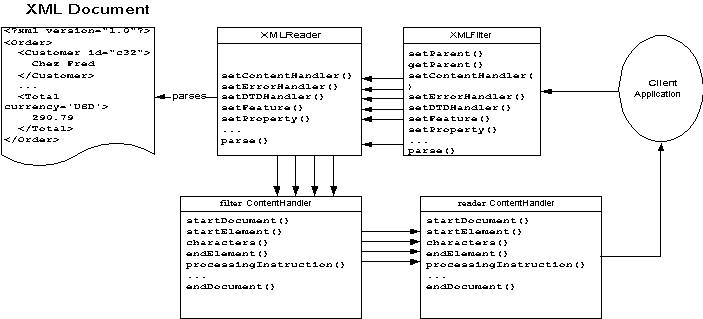
Since the filter sits in the middle between the real parser and the client application, it can change the stream of events that gets passed back and forth between the two. For example, it can convert VML to SVG on the fly. It can replace xinclude:include elements with the documents they point to. It can add namespaces to elements and attributes that don’t normally have them. Alternately it can work with the stream without actually changing the data itself. For example, it could log all SOAP requests that pass through it to a database. This wouldn’t necessarily change the data passing through the filter in any way, but it could help implement transactions with rollback and/or journaling to protect against data corruption in the event of a system crash.
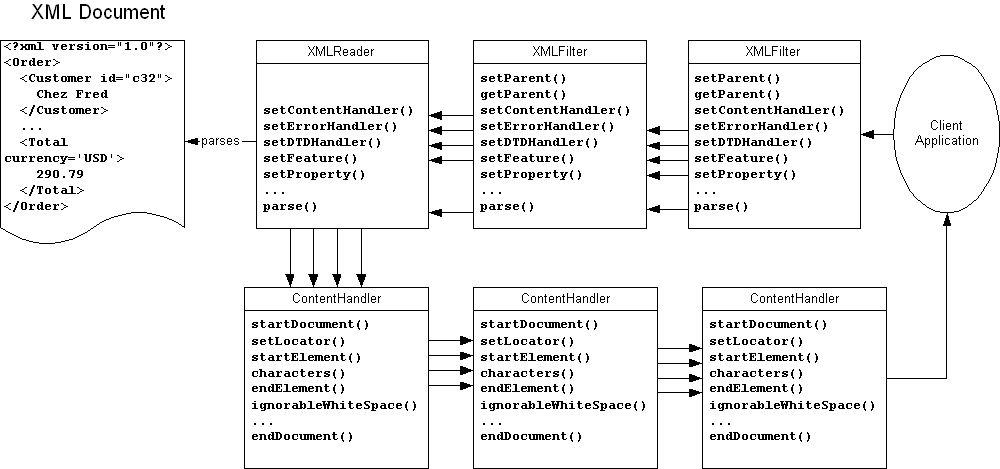
The XMLFilter interface is a subinterface of XMLReader. Therefore, rather than chaining a filter directly to the parser that’s reading the actual document, you can instead chain it to another filter. And this filter can be chained to another filter, and this filter can be chained to another filter, and so on, for as many filters as necessary, as diagrammed in Figure 8.3. For example, this allows you to add namespaces to a document, convert VML to SVG, and resolve XIncludes, all while parsing a single document. The document the client application receives can actually be quite different from the text file stored on a disk somewhere, depending on how many filters there are and how much they change the original data.
As a final trick, filters can present data that is not XML to an application as if it were XML. In other words, you can write a parser for some non-XML data such as tab-delimited text files, and provide an XMLReader interface through a filter to hide the fact that what’s being parsed isn’t really XML!